

























Вебмастеры могут влиять на то, как поисковые системы будут индексировать сайты. Они закрывают страницы для анализа, помечают предпочтительные URL, чтобы скрывать технические разделы, дублированный или устаревший контент и т.д.
Зачем закрывать страницы от индексации
Закрытие страниц от индексации помогает защитить конфиденциальную информацию и оптимизировать работу сайта. Некоторые разделы, такие как административные панели, черновики или тестовые страницы, содержат данные, которые не должны быть доступны в поисковых результатах. Блокировка их индексации предотвращает случайное отображение этой информации в выдаче, снижая риски утечки.
Еще одна важная причина — управление бюджетом индексации. Крупные сайты с тысячами страниц сталкиваются с ограничением на количество сканируемых поисковыми роботами страниц за определенный период. Если закрыть от индексации менее значимые разделы (например, фильтры и сортировки в интернет-магазинах), можно перенаправить ресурсы на индексацию ключевого контента, ускоряя его появление в поиске.
Также ограничение индексации необходимо во время разработки или масштабного обновления сайта. Если не закрыть доступ поисковым ботам, в выдаче могут появиться незавершённые страницы, что негативно скажется на пользовательском опыте и репутации ресурса. Временный запрет индексации позволяет избежать этой проблемы, обеспечивая корректное отображение контента после завершения работ.
robots.txt — блокировка на уровне обхода
Robots.txt — это текстовый файл, который указывает поисковым роботам, какие страницы или разделы сайта можно сканировать, а какие — нет. В нем можно полностью запретить краулерам обходить конкретные страницы или разделы.
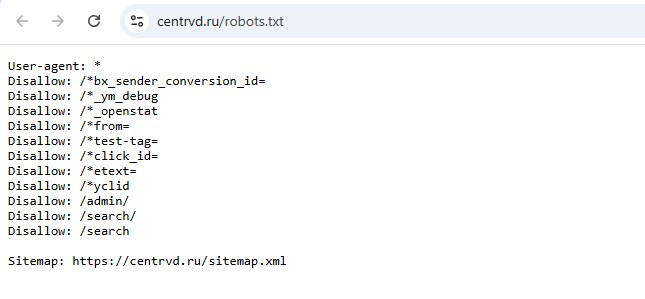
Что делает директива Disallow
Директива Disallow в файле robots.txt указывает поисковым роботам, какие разделы или страницы сайта им нельзя сканировать и индексировать.
Пример для запрета сканирования папки /admin/:
- User-agent: * (звезда означает, что инструкция создана для всех поисковых систем)
- Disallow: /admin/
При использовании директивы стоит помнить, что страницы все еще остаются доступными по прямой ссылке. Также она не гарантирует исключение из индекса. Для этого используется Noindex.
Ограничения robots.txt: когда он не сработает
Ограничения, установленные в robots.txt, не всегда работают. Если вебмастер закрыл доступ к странице в файле, она все равно может быть просканирована при наличии ссылок с других сайтов.
Noindex — исключение из индекса после обхода
Noindex — это директива, которая запрещает поисковым системам добавлять конкретную страницу в индекс, даже если роботы могут сканировать её содержимое.
Где и как применять noindex (мета-тег и HTTP-заголовок)
Есть 2 способа использовать noindex:
- Мета-тег. Такой вариант подходит для настройки ограничений для отдельных страниц и при отсутствии доступа к серверу.
- HTTP-заголовок. Позволяет массово закрыть группу страниц. Данный метод также подходит для файлов (например, картинок) и динамических разделов.
Мета-тег указывается в заголовке <head>. Пример:
<html>
<head>
<meta name=»robots» content=»noindex»>
</head>
<body>
…
</body>
</html>
С HTTP-заголовком немного сложнее, т.к. его настройка зависит от особенностей веб-сервера:
- PHP — header(«X-Robots-Tag: noindex», true);
- Nginx — location ~* /private/ {
add_header X-Robots-Tag «noindex»;
} - .htaccess (Apache) — <Files «secret.pdf»>
Header set X-Robots-Tag «noindex»
</Files>
Влияние на crawl budget и индексацию
Noindex не влияет на crawl budget (бюджет сканирования), но контролирует индексацию. Краткое описание:
- Краулинговый бюджет: Поисковые роботы сканируют страницы с noindex, но не добавляют их в индекс. Это значит, они тратят бюджет обхода на них, хотя и не показывают в поиске.
- Индексация: Страницы с noindex исключаются из поисковой выдачи, даже если робот их просканировал.
Совместимость с директивами robots.txt
Noindex не совместима с директивами в файле robots.txt. Чтобы директива noindex работала, нельзя закрывать доступ к странице. В противном случае робот не сможет обработать код и не обнаружит метатег.
Canonical — указание предпочтительного URL
Атрибут (rel=»canonical») указывает поисковым системам на основную (главную) версию страницы среди дублирующегося или похожего контента.
Принцип работы тега rel=»canonical»
Тег <link rel=»canonical» href=»URL»> сообщает поисковым системам, какая версия страницы является основной (канонической) среди дублирующегося или очень похожего контента. Благодаря указанию тега краулеры определяют основную страницу, передают весь вес ей и не накладывают санкции за дубли.
Когда использовать canonical вместо noindex
Основное правило:
- canonical — когда у вас есть похожие или дублирующиеся страницы, но одна из них — основная.
- noindex — когда страница вообще не должна попадать в поиск (например, служебные или конфиденциальные данные).
Сравнение методов: когда использовать каждый
Эти три инструмента помогают управлять индексацией и сканированием сайта, но каждый решает разные задачи. Вот когда и как их применять:
- canonical:
- Зачем: Объединить дубли страниц (фильтры, параметры URL).
- Пример кода: <link rel=»canonical» href=»основная-страница»>.
- Особенности: Не удаляет дубли, но указывает поисковикам главную версию.
- noindex:
- Зачем: Полностью убрать страницу из поиска (личные кабинеты, черновики).
- Пример кода: <meta name=»robots» content=»noindex»> или HTTP-заголовок.
- Особенности: Страница сканируется, но не индексируется.
- robots.txt
- Зачем: Запретить сканирование (админки, технические разделы).
- Пример кода: Disallow: /path/ в файле robots.txt.
- Особенности: Не гарантирует исключение из индекса — нужен noindex.
Ошибки при закрытии от индексации и их последствия
При настройке robots.txt и использовании тегов вебмастеры нередко допускают ошибки, из-за которых возникают проблемы с индексацией.
Закрытие важных страниц или SEO-страниц
Одна из распространенных ошибок вебмастеров — случайное применение тегов noindex/Disallow к ключевым страницам (категории, статьи, главная). Из-за этого страницы перестают отображаться или обновляться в индексе. Если быстро не устранить ошибку, то в будущем восстановить позиции станет сложно.
Конфликты между мета-тегами, robots.txt и canonical
Приведем 3 примера возможных конфликтов:
- Ошибка 1: Disallow в robots.txt + noindex на странице. Робот не зайдёт на страницу и не увидит noindex → URL останется в индексе.
- Ошибка 2: canonical + noindex на одной странице. Из-за этого возникают противоречивые сигналы. Поисковики чаще игнорируют canonical и следуют noindex.
- Ошибка 3: Неправильный canonical (ссылка на несуществующую страницу). Дубли остаются в индексе, вес не передается.
Заключение
При работе с сайтом важно использовать robots.txt и теги для управления индексацией. Благодаря им поисковики понимают, как взаимодействовать с ресурсом, расходовать бюджет, обрабатывать дубли и т.д. Поэтому вебмастерам важно разобраться в доступных инструментах и применять их.